· Nolwen Brosson · Blog · 17 min read
Les alternatives aux LLMs : World Models, VLA, SSM, etc.
L’horizon actuel de l’IA et ses limites
Depuis 2022, l’IA est devenue un partenaire de conversation accessible à tous, modifiant notre manière d’interagir avec la technologie. Les grands modèles de langage, ou LLMs, ont été au cœur de cette transformation, faisant du langage naturel une interface utilisateur d’une simplicité inédite. Pourtant, cette avancée n’est qu’un point de départ.
Une de leurs limites est conceptuelle : les LLMs sont comme des esprits brillants dans une pièce vide. Ils sont déconnectés du monde physique, des événements en temps réel et de la capacité de « voir » ou de « créer » au-delà du texte. Ils peuvent décrire une action, mais pas la réaliser. Ils peuvent résumer un événement passé, mais pas réagir à une situation présente.
Mais il existe une autre limite, plus structurelle encore: leur appétit démesuré en puissance de calcul. L’architecture même des LLMs: massive, dense, coûteuse, implique que chaque requête consomme une quantité d’énergie et de ressources hors du commun. Plus le modèle est grand, plus il est cher à entraîner, à maintenir, et à faire tourner. Cette dépendance à des grosses infrastructures pose une question simple: comment rendre ces systèmes scalables et durables à long terme?
Pour l’instant, la réponse n’est pas évidente.
Cet article explore cinq architectures émergentes conçues pour surmonter ces barrières. Chacune propose une approche différente pour doter l’IA de nouvelles capacités, dessinant un futur de l’IA plus diversifié. L’objectif n’est pas de prédire “le remplaçant du LLM”, mais de clarifier quelles architectures répondent aux besoins que les LLMs ne peuvent pas adresser.
Les World Models : l’IA dotée d’un simulateur interne
Les modèles World Models émergent réellement en 2018, avec les travaux de David Ha et Jürgen Schmidhuber (lien vers le papier de recherche). Leur idée naît d’un constat: pour apprendre efficacement, une IA ne doit pas seulement réagir au monde, elle doit d’abord se construire une représentation interne de ce monde, comme un animal qui développe une intuition des lois physiques avant de savoir marcher.
Les World Models fonctionnent en construisant un simulateur compressé de leur environnement. Concrètement, trois modules coopèrent :
- un encodeur (
V) transforme les observations brutes (images, capteurs…) en un espace latent beaucoup plus simple. À chaque nouvelle observation réelle, l’encodeur met à jour cet espace latent.- Exemple: Un robot voit une table avec un cube dessus. L’encodeur transforme l’image en quelques variables: position approximative du cube, orientation, distance à la main du robot. Pas besoin de pixels: juste l’essentiel pour comprendre la scène.
- un modèle de transition (
M) prend le résumé fait par l’encodeurV, et prédit ce qui va se passer ensuite (l’évolution de cet espace latent au fil du temps). Puis, il vérifie si sa prédiction correspond à la réalité. La différence prédiction vs réalité permet de corriger le modèle interne.- Exemple: Le robot avance sa main vers le cube. Le modèle de transition prédit : «Si la main se déplace de 5 cm, la distance au cube doit diminuer.» Puis il compare cette prédiction à ce que l’encodeur
Vdit vraiment après le mouvement. S’il s’est trompé, il ajuste sa compréhension du mouvement.
- Exemple: Le robot avance sa main vers le cube. Le modèle de transition prédit : «Si la main se déplace de 5 cm, la distance au cube doit diminuer.» Puis il compare cette prédiction à ce que l’encodeur
- un contrôleur décide des actions à entreprendre en se basant uniquement sur le modèle interne, le fameux univers simulé, qui correspond à
V&M. L’action est exécutée dans le monde réel, et le résultat réel est de nouveau comparé à ce que le modèle interne avait prévu, ce qui affine encore les modulesVetM.- Exemple: Le robot décide de pousser le cube vers la droite. Le modèle interne prédit que le cube va glisser de 3 cm. Le robot pousse réellement le cube. La caméra observe qu’il a glissé… de 1 cm, pas 3. Le contrôleur corrige alors ses futures décisions, et le modèle interne corrige sa physique approximative.
Il y a donc deux étapes qui permettent de mettre à jour le modèle interne: la 2. (observation) et la 3. (action). Un peu comme si au tennis, afin de progresser, nous allions non seulement regarder des matchs (observation), mais également en jouer (action)
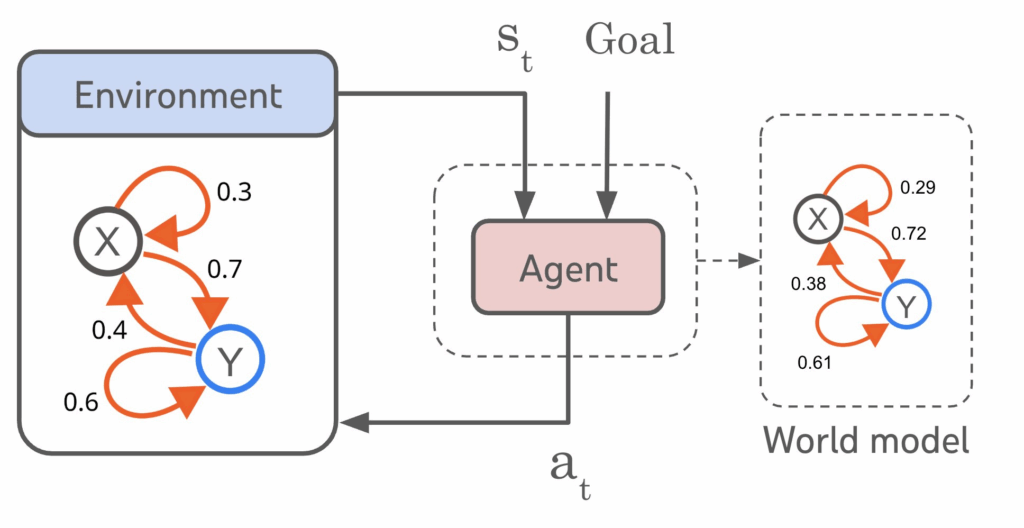
Le schéma ci-dessus montre comment un World Model permet à un agent de se construire une représentation interne de son environnement. L’agent observe l’état réel s_t et exécute une action a_t, qui modifie les transitions dans le monde physique (à gauche). En parallèle, il apprend un simulateur interne (à droite), où les états possibles (X, Y) et leurs probabilités de transition sont continuellement ajustés pour refléter la réalité. En comparant les transitions prédites par son modèle interne à celles observées dans l’environnement, l’agent corrige et améliore sa compréhension du monde, ce qui lui permet d’anticiper, planifier et agir de manière plus intelligente.
Cette capacité de simulation interne est particulièrement pertinente dans plusieurs domaines :
- Robotique : Un robot peut apprendre à empiler des objets en simulant la physique en interne, évitant des milliers de tentatives physiques coûteuses et lentes.
- Conduite autonome : Une voiture peut prédire la trajectoire probable d’un scooter qui se faufile sur le périphérique parisien, au lieu de simplement réagir à sa position actuelle.
- Apprentissage par renforcement : L’IA explore des millions de possibilités dans son modèle interne avant de choisir la meilleure stratégie, ce qui accélère drastiquement l’apprentissage.
Contrairement à un LLM qui peut décrire comment conduire, un World Model apprend à anticiper des événements dynamiques spécifiques, car il possède un modèle mental de la physique, du mouvement et de la causalité. L’article fondateur de Ha & Schmidhuber, World Models (2018), a montré que cette approche permet des apprentissages plus sûrs, plus rapides et plus proches des mécanismes perceptifs des animaux.
Et la suite ?
Les prochaines évolutions de ces modèles visent à :
- rendre les simulateurs plus fidèles, capables d’intégrer la physique, les intentions humaines, et des environnements ouverts
- les rendre interactifs en temps réel, afin que les agents puissent corriger et mettre à jour leur modèle interne en permanence
- fusionner LLMs et World Models, pour créer des agents capables à la fois de raisonner en langage naturel et de simuler des scénarios complexes dans un espace latent
Si les LLMs savent “parler du monde”, les World Models visent à comprendre et prédire le monde. Et leur combinaison annonce peut-être la prochaine grande rupture de l’IA.
Les modèles VLA : connecter la vision à l’action
Les modèles VLA (Vision-Language-Action) apparaissent réellement à partir de 2022-2023, avec les travaux de Google DeepMind et Stanford, dans un contexte où la robotique avait besoin d’unification: jusqu’ici, la vision, le langage et l’action étaient traités par des systèmes séparés. L’idée des VLA naît d’une intuition simple: pour qu’un agent puisse comprendre une instruction humaine, percevoir son environnement et agir dessus, il faut réunir ces trois dimensions dans un seul modèle.
Les modèles VLA fonctionnent en alignant ce que l’agent voit, ce qu’on lui dit, et ce qu’il doit faire, dans un espace représentationnel commun. Concrètement, trois modules coopèrent :
- un encodeur visuel (
V) extrait des informations des images ou du flux vidéo, les transformant en un espace latent cohérent avec le langage.- Exemple: Le robot observe une cuisine. L’encodeur visuel en extrait: la position de la tasse, la présence d’une bouteille d’eau, l’ouverture du tiroir. On ne garde pas les pixels, mais les objets et leurs relations.
- un encodeur de langage (
L) convertit une instruction humaine en une représentation compréhensible par le modèle. Cet encodage est ensuite aligné avec la perception visuelle pour décider de l’action.- Exemple : On dit au robot : « Remplis la tasse d’eau. » L’encodeur de langage traduit cette phrase en une représentation latente qui identifie les concepts tasse, eau, remplir, puis les associe aux éléments vus dans la scène.
- un module d’action (
A) prédit la séquence d’actions nécessaires pour accomplir la tâche, en intégrant à la fois les latents visuels et linguistiques. La boucle perception → instruction → action est en permanence confrontée à la réalité : si le robot agit et que le résultat n’est pas celui prévu, le modèle se corrige.- Exemple : Le robot tente de saisir la tasse pour la placer sous la bouteille. S’il la saisit mal et qu’elle glisse, la caméra renvoie l’erreur. Le module ajuste alors ses futures actions pour corriger sa “compréhension” de la manipulation.
Cette boucle intégrée : voir → comprendre → agir → vérifier, permet aux modèles VLA de réaliser des tâches complexes dans des environnements ouverts, simplement à partir d’instructions humaines formulées en langage naturel.
Cette capacité est particulièrement pertinente dans plusieurs domaines :
- Robotique domestique : Un robot peut exécuter des commandes floues comme « Range la cuisine » ou « Mets la table », en interprétant visuellement la scène et en planifiant une série d’actions adaptées.
- Industrie : Une machine peut suivre des instructions verbales pour assembler un objet, ajuster une pièce ou identifier un élément défectueux.
- Assistants interactifs : L’agent peut comprendre un contexte visuel (“la boîte est derrière toi”) et agir dessus, une compétence essentielle pour les robots compagnons ou les agents de terrain.
Contrairement à un LLM, qui peut expliquer comment exécuter une tâche mais ne peut pas la réaliser, un modèle VLA relie perception, langage et action dans une même boucle. Les travaux pionniers, comme PaLM-E (2023) ou RT-2 de Google, montrent que cette approche permet de créer des agents polyvalents, capables de comprendre une scène, d’interpréter une intention et de passer à l’action avec une étonnante fluidité.
Et la suite ?
Les prochaines évolutions des modèles VLA visent à :
- améliorer la compréhension visuelle dans des environnements non structurés, là où les objets ne sont ni propres ni bien alignés
- réduire la dépendance aux données robotique coûteuses, en exploitant davantage les simulations ou les vidéos non annotées
- combiner VLA et World Models, afin de donner aux robots la capacité non seulement d’exécuter des instructions, mais aussi de simuler l’avenir avant d’agir
- intégrer des modules de sécurité permettant aux robots de comprendre les risques (verre fragile, objets chauds, humains proches)
Si les LLMs permettent de communiquer avec une machine, les modèles VLA lui permettent d’écouter, de comprendre, et surtout d’agir. Leur convergence avec les World Models pourrait bien ouvrir la voie à des agents physiques réellement intelligents.
Les modèles State-Space : une nouvelle architecture pour les séquences
Les modèles State-Space Models (SSM) prennent leur essor entre 2021 et 2023 avec les travaux de Stanford, Meta et Carnegie Mellon, dans un contexte où l’on cherchait une alternative aux Transformers, devenus trop coûteux et trop lents pour des séquences longues (papier de recherche). L’idée des SSM naît d’un constat simple: pour traiter du texte, de l’audio ou des capteurs sur des milliers ou millions d’étapes, il faut une architecture capable de mémoriser à long terme, traiter rapidement, tout en restant scalable, ce que les LLMs traditionnels ont du mal à faire.
Les State-Space Models fonctionnent en représentant une séquence à travers une structure interne dynamique appelée état, qu’ils mettent à jour pas à pas. Contrairement aux Transformers qui comparent chaque token à tous les autres (ce qui explose en coût quadratique), les SSM utilisent un mécanisme linéaire en temps : une véritable révolution pour les séquences longues. Là où un Transformer doit tout re-calculer en permanence, un SSM n’a qu’à faire “avancer l’état” : une petite mise à jour à chaque pas. Concrètement, trois modules coopèrent :
- un encodeur d’entrée transforme chaque élément de la séquence (mot, pixel, fragment audio…) en une représentation compacte adaptée au modèle.
- Exemple : Pour une phrase, l’encodeur convertit chaque mot en un vecteur qui capture sa signification, exactement comme pour un LLM classique.
- un module d’état (
S) met à jour une mémoire interne en fonction des nouvelles entrées, via une équation mathématique. Cette mémoire évolue comme un petit système dynamique.- Exemple : Si le texte raconte une histoire, l’état garde en mémoire le protagoniste, l’endroit et le contexte, sans devoir relire tous les tokens précédents. Avec un seul vecteur, le modèle “sait” où il en est dans la séquence.
- un module de sortie génère la prédiction suivante (mot, action, classification…) en se basant sur l’état courant. La sortie est ensuite comparée aux données réelles, permettant de corriger l’évolution de l’état.
- Exemple : Si le modèle prédit le prochain mot d’une phrase et se trompe, il met à jour la dynamique interne pour affiner sa compréhension grammaticalo-sémantique.
Cette boucle : encoder → mettre à jour l’état → prédire → comparer, permet à un State-Space Model de naviguer dans des séquences extrêmement longues (textes, vidéos continues, signaux audio) tout en gardant une vraie mémoire temporelle, ce que les LLMs simulent difficilement.
Cette capacité est particulièrement pertinente dans plusieurs domaines :
- Traitement de séquences longues : analyser des documents de 500 pages, du code massif ou des logs système continus.
- Audio & parole : transcriptions longues, compréhension d’histoires orales, musique, conversations sans coupure.
- Vidéo : suivi d’objets, analyse d’événements continus, compréhension de longues scènes.
- Capteurs & IoT : données continues sur des millions de points, impossible à gérer avec des Transformers classiques.
Contrairement à un LLM, dont le coût explose dès qu’on dépasse quelques dizaines de milliers de tokens, un modèle SSM reste stable, rapide, et capable d’apprendre des dépendances à très long terme grâce à sa dynamique interne. Des modèles comme Mamba (2023) ou S4 démontrent qu’on peut obtenir des performances proches — voire supérieures — aux Transformers, tout en divisant le coût par 10 ou 20.
Et la suite ?
Les prochaines évolutions des modèles State-Space visent à :
- remplacer progressivement les Transformers dans les tâches séquentielles où la longueur explose (code, audio, vidéo, logs)
- introduire des SSM hybrides, où la dynamique interne est renforcée par du raisonnement symbolique ou des modules mémoire externes
- entraîner des modèles plus petits mais plus intelligents, grâce à une utilisation optimale du contexte
- combiner SSM et LLMs, pour obtenir des modèles capables de raisonner comme un LLM tout en traitant des séquences infinies
- créer des agents temps réel, capables de réagir instantanément à des flux continus sans recalculer toute l’attention
Si les LLMs actuels représentent une forme d’intelligence “statique” et coûteuse, les State-Space Models proposent une intelligence plus fluide, plus rapide, plus continue, conçue pour des contextes réels.
Et c’est pour cela que beaucoup les voient déjà comme la prochaine grande architecture de modèles, potentiellement capable de remplacer les LLMs dans de nombreuses tâches d’ici quelques années.
| Critère | Architecture Transformer (base des LLMs) | Architecture State-Space (Mamba) |
|---|---|---|
| Complexité de calcul | Quadratique (coût augmente exponentiellement avec la longueur) | Quasi-linéaire (coût augmente proportionnellement à la longueur) |
| Utilisation de la mémoire | Très élevée pour les longues séquences | Constante et faible, indépendante de la longueur |
| Performance sur séquences très longues | Devient rapidement impraticable et coûteuse | Excellente, conçue pour des contextes étendus |
| Cas d’usage idéal | Tâches linguistiques de longueur modérée, raisonnement complexe | Génomique, séries temporelles, audio haute-fidélité, documents longs |
Pour des tâches comme l’analyse de brins d’ADN entiers ou de signaux médicaux en temps réel, les SSM ne sont pas seulement plus rapides, ils sont surtout plus pratiques.
Les modèles de diffusion avancés : générer la réalité
Nous connaissons déjà le succès des modèles de diffusion pour la génération d’images 2D, avec des outils comme Midjourney ou DALL-E. L’idée des modèles de diffusion naît de ce principe: au lieu d’essayer de créer directement une image ou un son parfait, l’IA apprend d’abord à comprendre comment le bruit aléatoire peut se transformer progressivement en réalité.
Une fois cette compétence acquise, il suffit d’inverser le processus pour générer une réalité totalement nouvelle à partir du bruit. Concrètement, trois modules coopèrent :
- un processus de bruitage qui ajoute progressivement du bruit aux données réelles (images, sons, mouvements), jusqu’à les rendre méconnaissables.
- Exemple : Une photo de chat devient de plus en plus floue, granuleuse, puis complètement aléatoire. Le modèle doit apprendre chaque étape intermédiaire.
- un modèle de débruitage (
ε-model) qui apprend à prédire, à chaque étape, comment retirer une petite quantité de bruit et se rapprocher de l’image originale.- Exemple : L’IA reçoit une image partiellement bruitée et doit deviner “à quoi elle ressemblait juste avant d’être dégradée”. En répétant cela des milliers de fois, elle apprend la structure interne des images.
- un processus de génération qui part d’un bruit aléatoire pur et applique le modèle de débruitage à l’envers, étape par étape, pour faire émerger une nouvelle donnée cohérente : image, audio, vidéo.
- Exemple : Après 50 à 150 étapes de raffinage, un simple bruit se transforme en un paysage montagneux photoréaliste, un portrait détaillé, ou une scène vidéo entièrement inventée.
Cette boucle : bruiter → prédire → débruiter → répéter, permet aux modèles de diffusion avancés de produire des images, des sons ou des vidéos d’une qualité exceptionnelle, souvent difficile à distinguer du réel.
Cette capacité est particulièrement pertinente dans plusieurs domaines :
- Génération d’images réalistes : portraits, illustrations, scènes complexes, produits, concepts, mondes imaginaires.
- Vidéo : séquences fluides, transitions cohérentes, mouvements naturels, où chaque image dépend des précédentes.
- Audio & musique : voix réalistes, bruitages, compositions musicales sans artefacts métalliques.
- Design & créativité : itérations rapides, prototypes visuels, styles artistiques complexes, variations infinies.
Contrairement aux LLMs, qui génèrent principalement du texte et peinent à manipuler la structure spatiale ou temporelle complexe, les modèles de diffusion capturent la géométrie du monde, sa texture, sa lumière, ses règles physiques implicites. Des modèles comme Stable Diffusion XL (2023), Imagen (Google) ou Sora (OpenAI, 2024) démontrent que les modèles de diffusion peuvent créer des scènes entières cohérentes, avec une compréhension implicite des objets, des ombres, des interactions et même de la causalité visuelle.
Et la suite ?
Les prochaines évolutions des modèles de diffusion visent à :
- accélérer le processus de génération, en réduisant les 50–200 étapes à quelques prédictions seulement
- intégrer la 3D native, pour créer des scènes manipulables, des mondes interactifs, ou des objets utilisables en AR/VR
- combiner diffusion et simulateurs internes, afin de générer des vidéos cohérentes non seulement visuellement mais aussi physiquement
- unifier les modalités, pour passer naturellement de texte → image → vidéo → audio dans une même architecture
- connecter diffusion et robots, pour permettre la génération de plans d’action visuels ou de scénarios simulés
Si les LLMs excellent dans le langage, les modèles de diffusion avancés excellent dans la production de réalité : images, sons, mouvements, textures, continuité temporelle.
Et c’est cette capacité: créer, simuler, représenter, qui en fait une brique essentielle de la prochaine génération d’IA multimodales.
Un écosystème d’intelligences spécialisées
Le futur de l’IA ne réside probablement pas dans un modèle unique, mais dans un écosystème diversifié d’outils spécialisés. Le LLM est un outil multifonction, mais pour des tâches spécifiques, nous aurons besoin d’instruments dédiés. On choisira un bras robotique (VLA) pour manipuler des objets, un analyseur à haute vitesse (SSM) pour les longues séquences de données, ou une imprimante 3D (modèle de diffusion) pour créer des objets.
La véritable innovation viendra de notre capacité à combiner ces modèles de manière intelligente. Le défi n’est plus seulement de créer des IA généralistes, mais de construire des intelligences sur mesure en orchestrant les bons outils pour les bonnes tâches. Ces alternatives aux LLM ne sont pas des concurrents, mais des compléments essentiels.
| Type de modèle | Modèles les plus connus | Applications & industries |
|---|---|---|
| LLMs (Transformers) | GPT-4/5, Claude, Llama 3, Gemini | Assistance, service client, génération de texte, automatisation métier, analyse documentaire |
| World Models | Dreamer (V1/V2), PlaNet, MuZero (partiellement) | Robotique autonome, jeux vidéo, simulation, planification, RL avancé |
| VLA (Vision-Language-Action) | PaLM-E (Google), RT-2 (DeepMind), OpenVLA | Robotique domestique, industrie, manipulation d’objets, assistants physiques |
| State-Space Models (SSM) | Mamba, S4, Hyena | Santé (ECG), finance (séries temporelles), génomique, audio longue durée, traitement de logs, analyse de code |
| Modèles de diffusion | Stable Diffusion XL, DALL-E 3, Imagen, Sora | Cinéma, publicité, design produit, jeu vidéo, simulation visuelle, réalité virtuelle |
| Modèles hybrides / multimodaux | Gemini, GPT-4o, Kosmos-XL | IA générale, agents multimodaux, analyse vidéo, assistance temps réel |