· Nolwen Brosson · Blog · 9 min read
Ace, the AI robot that beats top ping-pong players: how does it work?
Everyone has already seen a robot playing table tennis. But until now, no robot was really able to beat strong players over a full match. Ace is different.
A team of researchers published a study in Nature on April 22, 2026, about this system. They made it play against five high-level players and two professionals, in conditions close to official play. Ace won three out of five matches against the high-level players. It lost against both professionals.
So the robot is not yet at the very highest level. But it shows that a robot can be competitive in conditions close to the real world.
Why table tennis is a hard problem for a robot
For a human, table tennis feels natural. You see the ball, anticipate, move, and hit. But for a robot, there is a lot of technical complexity.
Between two ball contacts, there can be less than half a second. And there is also the question of spin. With rotation, the ball can reach 1,000 radians per second, which changes its trajectory, its bounce on the table, and its behavior when it touches the racket.
In other words, Ace has to answer three questions, very quickly:
Where is the ball?
How much spin does it have?
What movement should be made to return it correctly?
And it has to do all of this in real time, with a human opponent who is actively trying to make things difficult.
How Ace sees the ball
Ace uses two types of vision.
The first system is used to locate the position of the ball in space. To do this, the robot relies on nine standard cameras placed around the playing area. These cameras reconstruct the ball’s position in 3D, a bit like our two eyes help our brain estimate depth.
In Ace’s case, the system tracks the ball at 200 Hz, meaning 200 measurements per second, with an average error of 3 millimeters and an average latency of 10.2 milliseconds. Latency is the delay between the moment something happens and the moment the system can use that information.
10.2 milliseconds is obviously very short. But in a sport where everything happens within a few hundred milliseconds, every millisecond matters.
The second system measures the spin of the ball. For that, Ace uses event cameras. Unlike a standard camera, which captures full images like a sequence of photos, an event camera works differently: it only transmits changes detected in the scene. This is very useful when an object is moving quickly, because the system does not need to process full images unnecessarily.
This type of camera is particularly well suited to table tennis, because spin is difficult to measure with standard cameras. A study on table tennis ball spin estimation with an event camera explains that rotation is essential, but hard to observe directly, especially when the ball is moving fast.
Ace combines these sensors with tracking systems that keep the ball in view, then estimates the rotation using two methods: a convolutional neural network, or CNN, to get a fast response, and a more precise but slower method called contrast maximization.
The spin estimates are then sent to the control system at a variable frequency of around 400 to 700 Hz.
In simple terms: Ace does not just see the ball. It also tries to read its spin, like a good human player would.
Reinforcement learning: how Ace learns to play
At the core of Ace is reinforcement learning.
The idea is simple. You place an agent in an environment. It tries an action. It receives a reward if the action is good, or a penalty if it is bad, then it tries again. After many attempts, it learns which actions increase its chances of success.
In Ace’s case, the agent is the robot’s control system. The environment is a table tennis simulation. The action is the movement the robot must produce to hit the ball. The reward depends on the quality of the return.
An important point: Ace’s control policies were trained entirely in simulation. The robot did not need to hit millions of balls in the real world to learn.
The researchers created physical models, added noise to simulate sensor imperfections, and trained several policies capable of producing different types of shots.
This is an essential detail. In many robotics projects, the problem is not only learning. It is transferring what was learned in simulation to the real world. This is called sim-to-real.
Ace works because its training was designed to handle this gap.
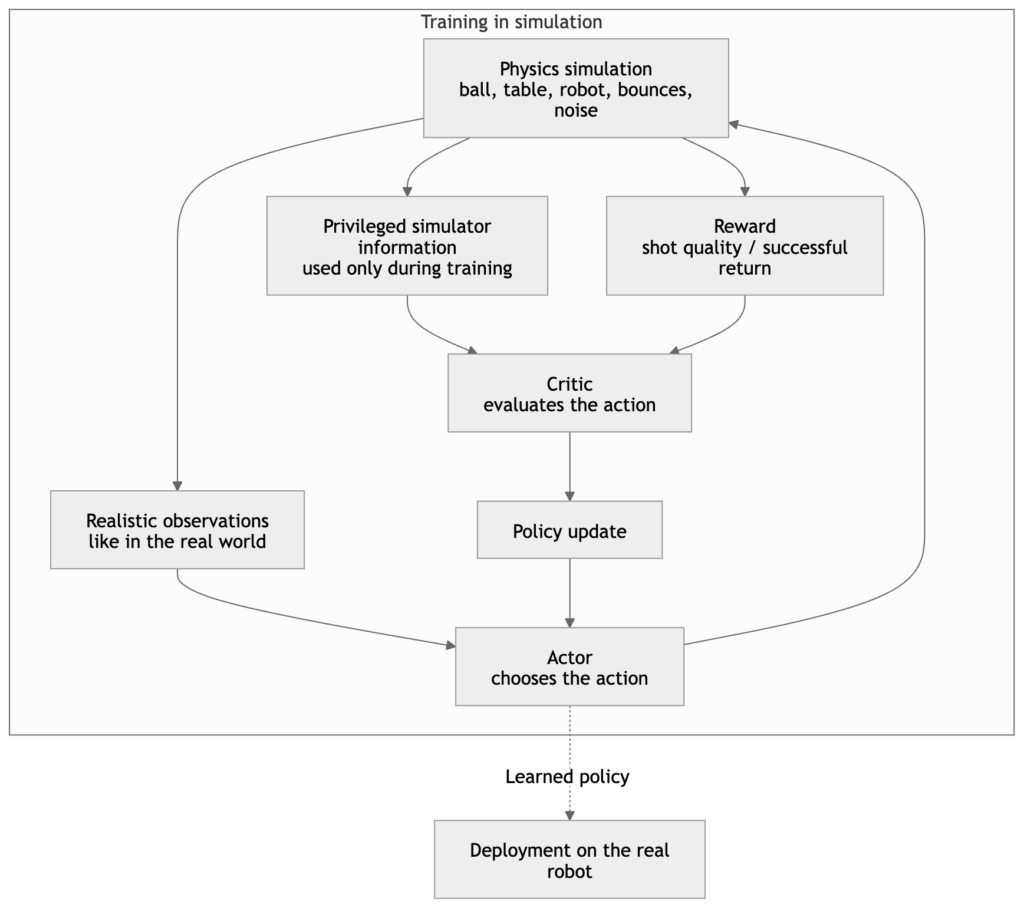
Actor-critic: the teacher and the player
The architecture used to train Ace is called asymmetric actor-critic. The term may sound intimidating, but the idea is fairly intuitive.
Imagine two roles.
The actor is the player. It decides what to do during the match. It receives imperfect information, just like in the real world: estimated ball position, estimated ball rotation, and robot state.
The critic is the teacher during training. It has access to cleaner information coming directly from the simulation. It can therefore better judge whether the chosen action was good or bad.
This approach is known in robotics. In a paper on asymmetric actor-critic for robot learning, researchers explain that perfect information from the simulator can be used to train a better critic, while keeping an actor that can act from imperfect observations in the real world.
During training, the teacher helps the player improve. But during the match, only the player acts. This is useful because the robot learns with precise help in simulation, while still being able to work with imperfect data in the real world.
This is one of the technical choices that prevents Ace from being good only inside a simulator.
How Ace decides its movement
During a rally, Ace queries its control policy every 32 milliseconds, or 31.25 times per second. Each time, the system receives the state of the ball, the state of the robot, and the recent history of measurements. It then produces an action.
But this action is not sent directly to the motor as a raw command.
It is transformed into a short trajectory lasting 32 milliseconds. Then, another system checks that the movement is feasible and does not cause a collision with the table or with the robot itself.
If the movement is considered dangerous, Ace executes a fallback trajectory, called a reset trajectory. The system therefore needs to be both fast and safe.
Hardware: the robot’s body matters as much as the AI
Ace would be nothing without its mechanical body. The robot was designed with eight degrees of freedom: two prismatic joints and six rotary joints.
A degree of freedom is an independent way of moving. The more degrees of freedom a robot has, the more varied movements it can produce.
The researchers explain that this configuration is the minimum needed to play competitive shots: controlling the position of the racket, its orientation, as well as the speed and direction of the hit.
Ace was designed to play over a real table area. Its arm can therefore reach the zones that a professional player uses during a rally.
But the robot also has to move at the right moment. Its motors are synchronized every millisecond, and even when it moves fast, the delay between the command and the actual movement remains below 5 milliseconds.
The AI can therefore choose the right shot, and the robot’s body can execute it almost immediately.
Results: Ace is strong, but still far from unbeatable
The tests took place in April 2025. Ace faced five players with more than ten years of training, then two professional players from Japan’s T.League.
The matches were played with official balls, an Olympic-sized playing area on the human player’s side, and without major simplifications of the usual rules.
Ace won three out of five matches against the high-level players. It lost both matches against the professionals.
What is interesting is how Ace wins. Humans mainly score with fast shots and heavy spin. Ace, on the other hand, wins more through consistency. It keeps a return rate above 75% up to 450 radians per second of rotation.
So Ace is not just a machine that hits hard. It is a machine that reads, controls, and returns the ball with impressive consistency.
What Ace teaches us about physical AI
Ace highlights a fundamental difference between digital AI and physical AI.
In a video game or a board game, AI receives a clean state: piece positions, score, fixed rules. In the real world, the state is always uncertain. Sensors have noise. Objects slide, spin, and bounce. Humans change strategy. Computation time is limited.
This makes table tennis an interesting benchmark, because it forces the system to solve several problems at once:
- fast perception
- physical prediction
- decision-making
- motor control
- opponent adaptation
The article concludes that the techniques used for Ace could apply to other areas where robots need to interact quickly and precisely with humans, such as service robotics or industrial production.
If a robot can react to a fast and unpredictable ball, it can also make progress in industrial environments that constantly change.
Ace’s current limitations
Unlike Go or chess, robots still cannot beat the best players in the world at table tennis.
Ace also remains a specialized system. It plays in an instrumented environment, with several cameras installed around the playing area and a robot designed specifically for this task.
The article highlights one last important challenge: modeling human behavior. To win a match, returning the ball is not enough. The robot has to understand the opponent’s game, vary its shots, anticipate choices, and exploit weaknesses.
That may be the next step: creating a robot capable of building real strategies.