· Nolwen Brosson · Blog · 14 min read
Alternatives to LLMs: World Models, VLA, SSM, etc.
The Current AI Horizon and Its Limitations
Since 2022, AI has become an accessible conversational partner for everyone, changing how we interact with technology. Large Language Models (LLMs) have been at the heart of this transformation, making natural language an unprecedentedly simple user interface. However, this advance is just a starting point.
One of their limitations is conceptual: LLMs are like brilliant minds in an empty room. They are disconnected from the physical world, real-time events, and the ability to « see » or « create » beyond text. They can describe an action but not perform it. They can summarize a past event but not react to a present situation.
But there is another, more structural limitation: their insatiable appetite for computing power. The very architecture of LLMs—massive, dense, costly—means that each query consumes an extraordinary amount of energy and resources. The larger the model, the more expensive it is to train, maintain, and run. This dependence on heavy infrastructure raises a simple question: how can we make these systems scalable and sustainable in the long term?
For now, the answer is not clear.
This article explores five emerging architectures designed to overcome these barriers. Each offers a different approach to equipping AI with new capabilities, outlining a more diverse future for AI. The goal is not to predict « the replacement for LLMs, » but to clarify which architectures address the needs that LLMs cannot.
World Models: AI with an Internal Simulator
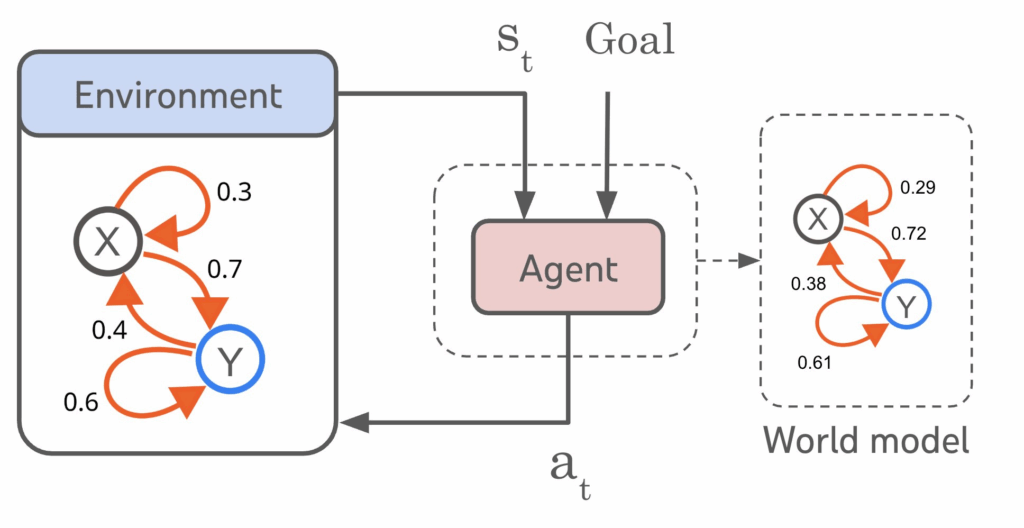
World Models truly emerged in 2018 with the work of David Ha and Jürgen Schmidhuber. Their idea stems from an observation: to learn effectively, an AI must not only react to the world; it must first build an internal representation of that world, like an animal developing an intuition of physical laws before learning to walk.
World Models work by building a compressed simulator of their environment. Specifically, three modules cooperate:
- An Encoder (V) transforms raw observations (images, sensors, etc.) into a much simpler latent space. With each new real observation, the encoder updates this latent space.
- Example: A robot sees a table with a cube on it. The encoder transforms the image into a few variables: approximate cube position, orientation, distance to the robot’s hand. No pixels needed: just the essentials to understand the scene.
- A Transition Model (M) takes the summary made by encoder V and predicts what will happen next (the evolution of this latent space over time). Then, it checks if its prediction matches reality. The difference between prediction and reality allows the internal model to be corrected.
- Example: The robot moves its hand towards the cube. The transition model predicts: « If the hand moves 5 cm, the distance to the cube should decrease. » Then it compares this prediction to what encoder V actually reports after the movement. If it was wrong, it adjusts its understanding of the movement.
- A Controller decides which actions to take based solely on the internal model (the famous simulated universe, corresponding to V & M). The action is executed in the real world, and the real result is again compared to what the internal model had predicted, further refining modules V and M.
- Example: The robot decides to push the cube to the right. The internal model predicts the cube will slide 3 cm. The robot actually pushes the cube. The camera observes it slid… 1 cm, not 3. The controller then corrects its future decisions, and the internal model corrects its approximate physics.
There are thus two steps that allow the internal model to be updated: step 2 (observation) and step 3 (action). It’s somewhat like in tennis, where to improve, we not only watch matches (observation) but also play them (action).
This internal simulation capability is particularly relevant in several domains:
- Robotics: A robot can learn to stack objects by simulating physics internally, avoiding thousands of costly and slow physical attempts.
- Autonomous Driving: A car can predict the probable trajectory of a scooter weaving through Parisian traffic, instead of just reacting to its current position.
- Reinforcement Learning: The AI explores millions of possibilities in its internal model before choosing the best strategy, drastically accelerating learning.
Unlike an LLM that can describe how to drive, a World Model learns to anticipate specific dynamic events because it possesses a mental model of physics, motion, and causality. The seminal article by Ha & Schmidhuber, World Models (2018), showed that this approach enables safer, faster learning closer to the perceptual mechanisms of animals.
What’s Next?
The future evolution of these models aims to:
- Make simulators more faithful, capable of integrating physics, human intentions, and open environments.
- Make them interactive in real-time, so agents can continuously correct and update their internal model.
- Fuse LLMs and World Models to create agents capable of both reasoning in natural language and simulating complex scenarios in a latent space.
If LLMs know how to « talk about the world, » World Models aim to understand and predict it. And their combination may herald the next major breakthrough in AI.
VLA Models: Connecting Vision to Action
VLA (Vision-Language-Action) models truly emerged around 2022-2023 with work from Google DeepMind and Stanford, in a context where robotics needed unification: until then, vision, language, and action were handled by separate systems. The idea behind VLAs stems from a simple intuition: for an agent to understand a human instruction, perceive its environment, and act upon it, these three dimensions must be united in a single model.
VLA models work by aligning what the agent sees, what it is told, and what it must do into a common representational space. Specifically, three modules cooperate:
- A Visual Encoder (V) extracts information from images or video streams, transforming it into a latent space consistent with language.
- Example: The robot observes a kitchen. The visual encoder extracts: the cup’s position, the presence of a water bottle, the drawer being open. It doesn’t keep pixels, but objects and their relationships.
- A Language Encoder (L) converts a human instruction into a representation understandable by the model. This encoding is then aligned with visual perception to decide on the action.
- Example: You tell the robot: « Fill the cup with water. » The language encoder translates this sentence into a latent representation that identifies the concepts cup, water, fill, then associates them with the elements seen in the scene.
- An Action Module (A) predicts the sequence of actions needed to accomplish the task, integrating both visual and linguistic latents. The perception → instruction → action loop is constantly confronted with reality: if the robot acts and the result is not as expected, the model corrects itself.
- Example: The robot attempts to grasp the cup to place it under the bottle. If it grasps it poorly and it slips, the camera feeds back the error. The module then adjusts its future actions to correct its « understanding » of manipulation.
This integrated loop—see → understand → act → verify—enables VLA models to perform complex tasks in open environments, simply from human instructions formulated in natural language.
This capability is particularly relevant in several domains:
- Domestic Robotics: A robot can execute vague commands like « Tidy the kitchen » or « Set the table, » by visually interpreting the scene and planning a series of adapted actions.
- Industry: A machine can follow verbal instructions to assemble an object, adjust a part, or identify a defective component.
- Interactive Assistants: The agent can understand a visual context (« the box is behind you ») and act on it, an essential skill for companion robots or field agents.
Unlike an LLM, which can explain how to perform a task but cannot execute it, a VLA model links perception, language, and action in the same loop. Pioneering work, like PaLM-E (2023) or Google’s RT-2, shows that this approach creates versatile agents capable of understanding a scene, interpreting an intent, and taking action with astonishing fluidity.
What’s Next?
The future evolution of VLA models aims to:
- Improve visual understanding in unstructured environments, where objects are neither clean nor well-aligned.
- Reduce dependence on expensive robotic data by leveraging simulations or unannotated videos more.
- Combine VLA and World Models to give robots the ability not only to execute instructions but also to simulate the future before acting.
- Integrate safety modules enabling robots to understand risks (fragile glass, hot objects, nearby humans).
If LLMs allow communication with a machine, VLA models allow it to listen, understand, and, most importantly, act. Their convergence with World Models could well pave the way for truly intelligent physical agents.
State-Space Models: A New Architecture for Sequences
State-Space Models (SSMs) gained traction between 2021 and 2023 with work from Stanford, Meta, and Carnegie Mellon, in a context where alternatives to Transformers were sought, as they had become too costly and slow for long sequences. The idea behind SSMs stems from a simple observation: to process text, audio, or sensor data over thousands or millions of steps, an architecture capable of long-term memory, fast processing, and scalability is needed, which traditional LLMs struggle with.
State-Space Models work by representing a sequence through a dynamic internal structure called a state, which they update step by step. Unlike Transformers, which compare each token to all others (leading to quadratic cost explosion), SSMs use a linear-time mechanism: a true revolution for long sequences. Where a Transformer must constantly recalculate everything, an SSM only needs to « advance the state »: a small update at each step. Specifically, three modules cooperate:
- An Input Encoder transforms each element of the sequence (word, pixel, audio fragment, etc.) into a compact representation suitable for the model.
- Example: For a sentence, the encoder converts each word into a vector capturing its meaning, just like a classic LLM.
- A State Module (S) updates an internal memory based on new inputs, via a mathematical equation. This memory evolves like a small dynamic system.
- Example: If the text tells a story, the state keeps the protagonist, location, and context in memory without needing to reread all previous tokens. With a single vector, the model « knows » where it is in the sequence.
- An Output Module generates the next prediction (word, action, classification, etc.) based on the current state. The output is then compared to real data, allowing the state’s evolution to be corrected.
- Example: If the model predicts the next word of a sentence and is wrong, it updates the internal dynamics to refine its grammatical-semantic understanding.
This loop—encode → update state → predict → compare—enables a State-Space Model to navigate extremely long sequences (texts, continuous videos, audio signals) while maintaining true temporal memory, which LLMs simulate with difficulty.
This capability is particularly relevant in several domains:
- Long Sequence Processing: Analyzing 500-page documents, massive codebases, or continuous system logs.
- Audio & Speech: Long transcriptions, understanding oral stories, music, uninterrupted conversations.
- Video: Object tracking, analysis of continuous events, understanding long scenes.
- Sensors & IoT: Continuous data over millions of points, impossible to manage with classic Transformers.
Unlike an LLM, whose cost explodes beyond a few tens of thousands of tokens, an SSM model remains stable, fast, and capable of learning very long-term dependencies thanks to its internal dynamics. Models like Mamba (2023) or S4 demonstrate that performance close to—or even superior to—Transformers can be achieved, while dividing the cost by 10 or 20.
What’s Next?
The future evolution of State-Space Models aims to:
- Gradually replace Transformers in sequential tasks where length explodes (code, audio, video, logs).
- Introduce hybrid SSMs, where internal dynamics are reinforced by symbolic reasoning or external memory modules.
- Train smaller but smarter models, thanks to optimal context usage.
- Combine SSM and LLMs to create models capable of reasoning like an LLM while processing infinite sequences.
- Create real-time agents capable of reacting instantly to continuous flows without recalculating all the attention.
If current LLMs represent a form of « static » and costly intelligence, State-Space Models propose a more fluid, faster, more continuous intelligence, designed for real-world contexts. This is why many already see them as the next major model architecture, potentially capable of replacing LLMs in many tasks within a few years.
| Criterion | Transformer Architecture (Basis of LLMs) | State-Space Architecture (Mamba) |
|---|---|---|
| Computational Complexity | Quadratic (cost increases exponentially with length) | Quasi-linear (cost increases proportionally to length) |
| Memory Usage | Very high for long sequences | Constant and low, independent of length |
| Performance on Very Long Sequences | Quickly becomes impractical and costly | Excellent, designed for extended contexts |
| Ideal Use Case | Linguistic tasks of moderate length, complex reasoning | Genomics, time series, high-fidelity audio, long documents |
For tasks like analyzing entire DNA strands or real-time medical signals, SSMs are not only faster, they are above all more practical.
Advanced Diffusion Models: Generating Reality
We already know the success of diffusion models for 2D image generation, with tools like Midjourney or DALL-E. The idea of diffusion models stems from this principle: instead of trying to create a perfect image or sound directly, the AI first learns to understand how random noise can gradually transform into reality.
Once this skill is acquired, it’s enough to reverse the process to generate a totally new reality from noise. Specifically, three modules cooperate:
- A Noising Process gradually adds noise to real data (images, sounds, movements) until they become unrecognizable.
- Example: A cat photo becomes increasingly blurry, grainy, then completely random. The model must learn each intermediate step.
- A Denoising Model (ε-model) that learns to predict, at each step, how to remove a small amount of noise and get closer to the original image.
- Example: The AI receives a partially noised image and must guess « what it looked like just before being degraded. » Repeating this thousands of times, it learns the internal structure of images.
- A Generation Process that starts from pure random noise and applies the denoising model in reverse, step by step, to make new coherent data emerge: image, audio, video.
- Example: After 50 to 150 refinement steps, simple noise transforms into a photorealistic mountain landscape, a detailed portrait, or an entirely invented video scene.
This loop—noise → predict → denoise → repeat—enables advanced diffusion models to produce images, sounds, or videos of exceptional quality, often difficult to distinguish from reality.
This capability is particularly relevant in several domains:
- Realistic Image Generation: Portraits, illustrations, complex scenes, products, concepts, imaginary worlds.
- Video: Fluid sequences, coherent transitions, natural movements, where each frame depends on the previous ones.
- Audio & Music: Realistic voices, sound effects, musical compositions without metallic artifacts.
- Design & Creativity: Rapid iterations, visual prototypes, complex artistic styles, infinite variations.
Unlike LLMs, which primarily generate text and struggle to manipulate complex spatial or temporal structure, diffusion models capture the geometry of the world, its texture, light, and implicit physical rules. Models like Stable Diffusion XL (2023), Imagen (Google), or Sora (OpenAI, 2024) demonstrate that diffusion models can create entire coherent scenes, with an implicit understanding of objects, shadows, interactions, and even visual causality.
What’s Next?
The future evolution of diffusion models aims to:
- Accelerate the generation process, reducing the 50–200 steps to just a few predictions.
- Integrate native 3D to create manipulable scenes, interactive worlds, or objects usable in AR/VR.
- Combine diffusion and internal simulators to generate videos coherent not only visually but also physically.
- Unify modalities to naturally transition from text → image → video → audio within the same architecture.
- Connect diffusion and robots to enable the generation of visual action plans or simulated scenarios.
If LLMs excel in language, advanced diffusion models excel in producing reality: images, sounds, movements, textures, temporal continuity. It is this ability—to create, simulate, represent—that makes them an essential building block for the next generation of multimodal AI.
An Ecosystem of Specialized Intelligences
The future of AI probably lies not in a single model, but in a diverse ecosystem of specialized tools. The LLM is a multifunctional tool, but for specific tasks, we will need dedicated instruments. One would choose a robotic arm (VLA) for manipulating objects, a high-speed analyzer (SSM) for long data sequences, or a 3D printer (diffusion model) to create objects.
The true innovation will come from our ability to combine these models intelligently. The challenge is no longer just to create generalist AIs, but to build tailored intelligences by orchestrating the right tools for the right tasks. These alternatives to LLMs are not competitors, but essential complements.
| Model Type | Most Well-Known Models | Applications & Industries |
|---|---|---|
| LLMs (Transformers) | GPT-4/5, Claude, Llama 3, Gemini | Assistance, customer service, text generation, business automation, document analysis |
| World Models | Dreamer (V1/V2), PlaNet, MuZero (partially) | Autonomous robotics, video games, simulation, planning, advanced RL |
| VLA (Vision-Language-Action) | PaLM-E (Google), RT-2 (DeepMind), OpenVLA | Domestic robotics, industry, object manipulation, physical assistants |
| State-Space Models (SSM) | Mamba, S4, Hyena | Healthcare (ECG), finance (time series), genomics, long-form audio, log processing, code analysis |
| Diffusion Models | Stable Diffusion XL, DALL-E 3, Imagen, Sora | Cinema, advertising, product design, video games, visual simulation, virtual reality |
| Hybrid / Multimodal Models | Gemini, GPT-4o, Kosmos-X | General AI, multimodal agents, video analysis, real-time assistance |